周末给网站做了若干调整,脱离了 jQuery,拥抱原生 JavaScript,主要调整如下:
更新到 infinite ajax scroll 3.0
自2015年以来,一直使用 infinite ajax scroll 以实现网站的滚动加载,去年 infinite ajax scroll 更新到了 3.0,与 2.x 版本最直接的区别是 3.0 舍弃了对 jQuery 的依赖,改用现代 JavaScript 技术构建。
以下是我使用的2.x版本的代码,通过自定义配置实现了前3页自动加载,后续页面手动加载的需求
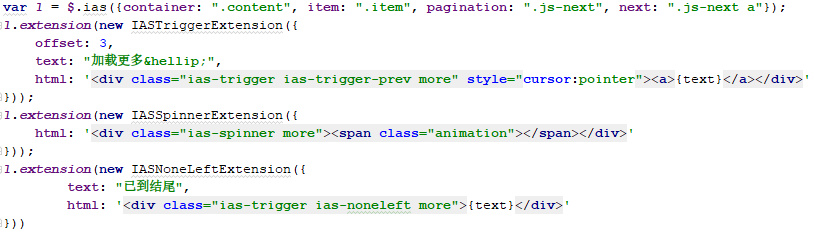
以下是切换到 3.0 后的代码,同样实现了前3页自动加载,后续页面手动加载的加载方式。去年就想着更新到 3.0了,囿于自动加载后转手动加载一直没搞定,这次终于搞定了。
var optionElement = document.querySelector('.content');
var iasHtml = '<div class="ias-spinner more"><span class="animation"></span></div><div class="ias-trigger more"><a>加载更多</a></div>';
optionElement.insertAdjacentHTML('beforeend', iasHtml);
var ias = new InfiniteAjaxScroll('.content', {
item: '.item',
next: '.next a',
pagination: '.next',
spinner: {
element: '.ias-spinner',
delay: 600,
show: function (element) {
element.style.display = 'block';
},
hide: function (element) {
element.style.display = 'none';
}
},
trigger: {
element: '.ias-trigger',
// 控制什么时候显示加载更多按钮,目前的配置是自动加载前3页
when: function (pageIndex) {
return pageIndex > 2;
},
show: function (element) {
element.style.display = 'block';
},
hide: function (element) {
element.style.display = 'none';
}
}
});
ias.on('last', function () {
// 删除 content 元素下的含有 more 元素的节点, 并插入新节点(直接设置 className, 点击标签会报错)
while (document.querySelector('.content .more')) {
var deleteNode = document.querySelector('.content .more');
deleteNode.parentNode.removeChild(deleteNode);
}
iasHtml = '<div class="ias-noneleft more">已到结尾</div>';
optionElement.insertAdjacentHTML('beforeend', iasHtml);
});
在 infinite ajax scroll 中集成 Prism
本次更新还给网站加了代码高亮插件 Prism 来实现代码高亮,并将之整合到 infinite ajax scroll 中:在 infinite ajax scroll 中集成 Prism
更新下拉菜单
更新前,下拉菜单依赖 jQuery 的 toggle 方法,通过切换 CSS 的 display 属性值(block/none)来实现。本次对此处的改造发现了以往一直存在的 bug:iOS 下浏览器文本框在发生点击(focus 事件)弹出虚拟键盘时,若页面不在初始位置(就是向上滑动了),系统会自动产生向上弹一下(scroll 事件)的动画效果,这跟我这里预设的页面向上滑动自动隐藏菜单的功能相冲突,导致刚一点搜索框菜单就被隐藏了。记得之前有朋友提醒给我,问题是我一直没法重现这个问题,这次无意间发现了,他很细心!
解决办法是监听到搜索框元素的点击事件(focus)时阻止执行自动隐藏菜单的操作。
更新 like 功能
更新前,like 依赖 jQuery 的 ajax,更新后使用了 XMLHttpRequest(XHR)对象以替代 ajax。
下面是一个简单的使用 XMLHttpRequest 发送异步请求的 JavaScript 示例:
var request = new XMLHttpRequest();
var requestUrl = '...';
var data = '...';
request.open('POST', requestUrl, true);
request.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8');
// 发送请求
request.send(data);
// onload
request.onload = function () {
if (this.status === 200) {
// 获取到返回的数据
e = JSON.parse(this.responseText);
console.log(e);
} else {
}
};
兼容 Safari 9
更新第一版后发现 js 在家里的老 iPad (Safari 9)上不能工作,排查发现问题由以下几个问题造成:
- Safari 9 不支持函数形参默认值;
- Safari 9 支持严格模式,但 Safari 9 在严格模式下对
setTimeout()作用域的处理好像跟更高版本有不一致行为(不确定,仅猜测),由于没有办法调试,只是简单地把setTimeout调用的函数放到外层来避免问题。
如何从 jQuery 迁移到 JavaScript
关于从 jQuery 迁移到 JavaScript 的若干建议或指南,除了事无巨细的 MDN JavaScript 在线文档,还有 You might not need jQuery 这个项目,它对 jQuery 转 JavaScript 的介绍详细到指明了各种方案的浏览器兼容性,感谢他们:
- You might not need jQuery
- MDN JavaScript 在线文档
- Essential Cheat Sheet: Convert jQuery to JavaScript